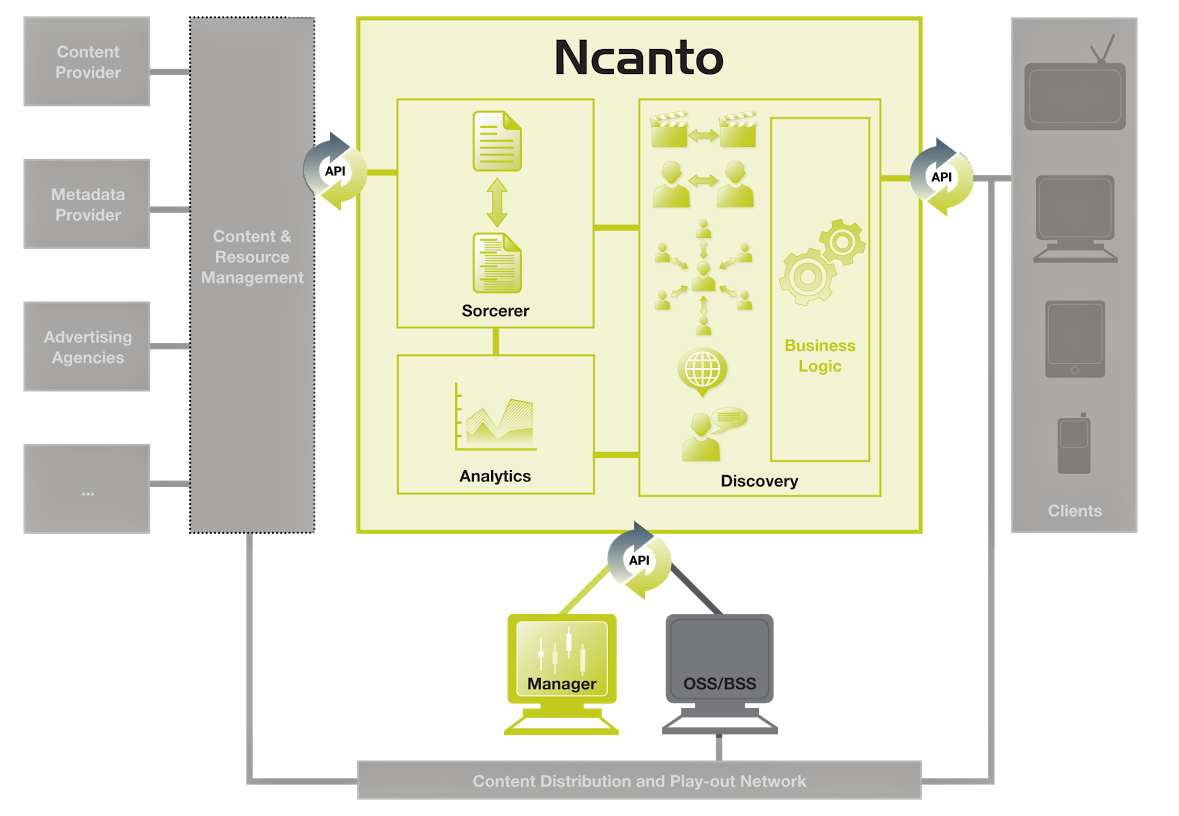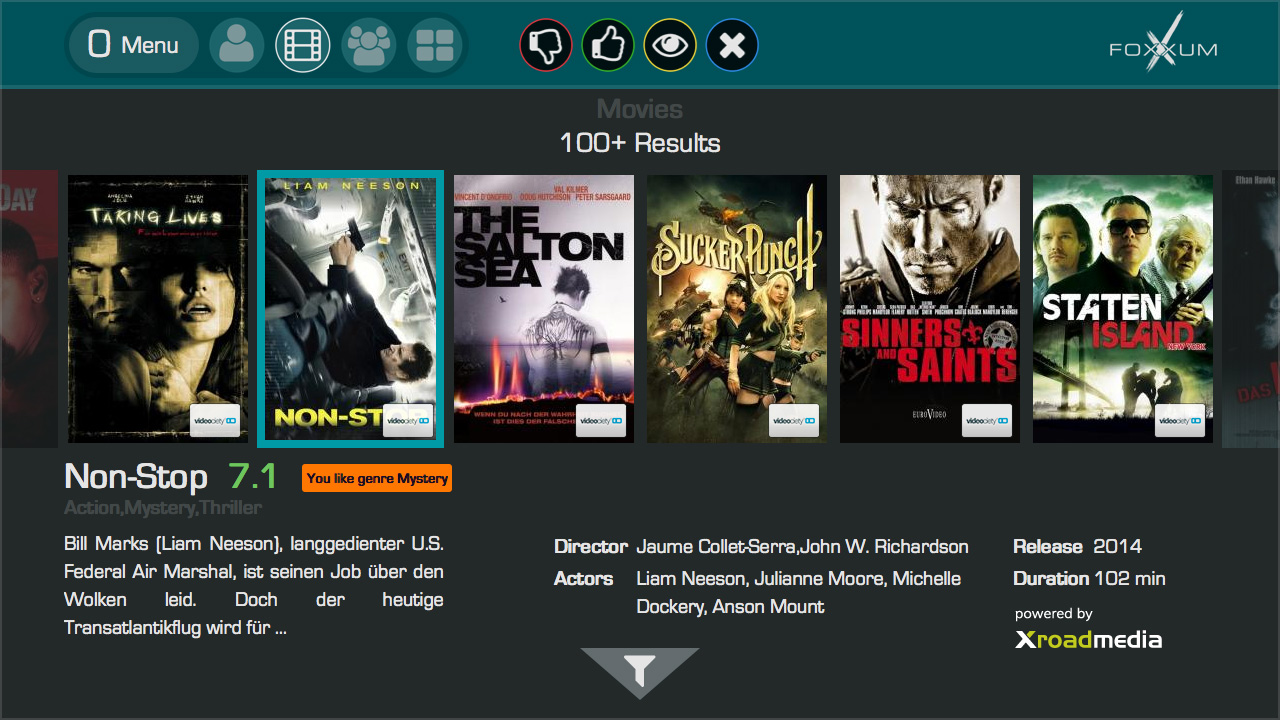
История систем рекомендаций
Сейчас мы воспринимаем сложные самообучающиеся компьютерные программы как данность и используем для их описания разные интересные термины: «большие данные» (big data), «искусственный интеллект» (artificial intelligence), «рекомендательные системы». Но началось все много лет назад в области знаний, которая называется машинным обучением (mashine learning). В 50-е годы в этой области науки были сформулированы математические подходы и описаны модели самообучающихся алгоритмов, которые до настоящего времени лежат в основе всех решений. Это, например, наивный байесовский классификатор или искусственная нейронная сеть.
В этой статье мы сфокусируемся на том, как развитие процессорной мощности пользовательских устройств позволило применить эти подходы для рекомендаций теле- и видеоконтента для пользователей, и рассмотрим прошлое, настоящее и будущее таких решений.
Первый этап развития рекомендательных систем — коллаборативная фильтрация
Первый цифровой видеомагнитофон, который пытался учесть предпочтения пользователей, чтобы автоматически записывать подходящие им передачи, появился в конце 1990-х. Устройство называлось TiVo и продавалось конечным пользователям такими брендами, как Sony и Philips (до выхода TiVo на IPO в 1999 компания Philips, в которой в то время работал автор этой статьи, являлась одним из совладельцев TiVo). В то время хорошо структурированных описаний для всех вещаемых телепередач не было и мощности пользовательских устройств для сложных вычислений тоже не хватало, поэтому в основу системы рекомендаций был положен алгоритм коллаборативной фильтрации.
Коллаборативная фильтрация основывается исключительно на сходстве поведения пользователей и не использует никаких описаний телепередач и фильмов или другой семантики. Если на двух устройствах TiVo в двух разных домохозяйствах зрители обычно выбирали одни и те же программы, а потом первый пользователь начинал регулярно смотреть какую-либо новую телепередачу, то эту телепередачу рекомендовали и второму пользователю. Все устройства TiVo ночью отправляли на центральный сервер данные о последовательностях кликов (какие именно кнопки нажимал пользователь, какие программы смотрел и записывал), на основании этих данных рекомендательный алгоритм на сервере вычислял персональные рекомендации, и они затем загружались на устройства. Такая организация процесса на центральном сервере позволяла, во-первых, сравнивать и находить зрителей с похожими вкусами, а во-вторых, не «грузить» видеомагнитофоны TiVo с их очень ограниченными вычислитель не «грузить» видеомагнитофоны TiVo с их очень ограниченными вычислительными возможностями. Несмотря на то, что решение не работало в реальном времени и иногда неправильно определяло интересы пользователя (см, например, «Мой видеомагнитофон считает, что я гей» — истории о том, как пользователи пытаются понять и повлиять на результаты рекомендаций), простота подхода быстро сделала его популярным в отрасли. Чемпионом применения стала компания Netflix, которая для своего бизнеса предоставления DVD-дисков в аренду привлекла команду разработчиков, настраивающих параметры рекомендательного движка коллаборативной фильтрации, и добивался год от года все лучших результатов.
Однако в середине 2000-х качество рекомендаций, которое может обеспечить алгоритм коллаборативной фильтрации, достигло некоторого предела. В надежде спасти ситуацию за счет коллективного разума в 2006 Netflix организовала конкурс Netflix Prize. Лучшие команды разработчиков в течение трех лет добились дальнейшего улучшения точности рекомендаций еще на 10%, но предложенные решения использовать на практике было нельзя — небольшое улучшение точности требовало совершенно неадекватных операционных затрат. Коллаборативная фильтрация как основной метод рекомендаций в видео зашла в тупик.
Второй этап развития рекомендательных систем — фильтрация по контенту
В процессе развития новых подходов к решению задачи на гребне волны оказались новые компании, в частности Jinni и Aprico (автор этой статьи являлся основателем и директором APRICO Solutions, которую финансировала Philips), которые поняли, что качественная информация о рекомендуемом контенте могла бы служить серьезной основой для тонкой подстройки под интересы зрителей. Эта новая волна исследований в основном использовала байесовскую классификацию, которая позволяет понять и оценить, почему пользователь предпочитает тот или иной контент. К примеру, если пользователь смотрит фильмы типа «Джеймса Бонда», но пропускает «Одиннадцать друзей Оушена», то система полагает, что когда речь идет о фильмах, этот пользователь любит боевики и приключения, но не особенно любит триллеры или детективы.
В Netflix сразу оценили перспективы нового направления семантического анализа описаний и снова решили заняться собственной разработкой. Как и Jinni, они стали создавать описания и классификаторы для фильмов своего каталога. Этот подход имеет ряд проблем, связанных с масштабированием, так как разумен и оправдан, только если каталог видео относительно мал и увеличивается медленно. Остальные компании, занимающиеся семантическими рекомендательными решениями, сфокусировались на классификации контента на основе метаданных, которые существовали на рынке. Netflix же опять отличился и постарался дойти до границ возможного. Его каталог жанров быстро вырос с исходных 560 вариантов до 93116, по данным на июль 2014 года, в числе которых были, например, такие как «эмоциональные драмы 80-х, получившие высокую оценку кинокритиков», куда в каталоге Netflix попадало лишь 2 фильма. И это опять было чересчур — категории, которым соответствуют один-два объекта, не годятся для анализа и становятся незначимыми для байесовского классификатора.
Третий этап развития рекомендательных систем -анализ контекста
Тем временем развитие облачных вычислений предоставило компаниям, разрабатывающим рекомендации, колоссальные возможности для проведения натурных тестов. Наша компания APRICO Solutions, как и другие исследователи, на основе этих тестов получила ясную информацию о том, в каком виде люди хотят получать рекомендации, как они реагируют и какую обратную связь готовы предоставлять. И оказалось, к изумлению многих разработчиков, что требованиям пользователей ни один конкретный рекомендательный алгоритм удовлетворить не может. Пользователям нужна комбинация редакторских рекомендаций, фильтрации по контенту на основе персональных предпочтений, рекомендаций сообщества людей с близкими вкусами, и чтобы в этих рекомендациях были удачные находки, а подбор контента соответствовал сиюминутному настроению и типу используемого устройства. При этом пользователь должен понимать, что это не какой-то там «Большой брат» следит за ним, а он сам может повлиять на результат. Сложные настройки предлагать не нужно, скажем, соотношение между редакторскими рекомендациями и фильтрацией по контенту определяет оператор, но, например, если рядом с рекомендованным фильмом указано, что данный фильм вам советуют посмотреть потому, что вам нравится Дженнифер Лопес, а она вам на самом деле не нравится, нужно иметь возможность прямо сразу это отметить и немедленно получить другие рекомендации.
Таким образом, после периода изучения кликов пользователя и после периода семантических рекомендаций мы пришли к новому этапу, в котором основную роль играет контекст: cиюминутные намерения, интересы и окружение пользователя. Ясно, что это снова другой подход, при котором рекомендательный движок должен давать результат сразу, как только будут получены данные о контексте, учитывать все варианты алгоритмов, пояснять рекомендации пользователю и давать ему постоянный контроль над параметрами. Компания XroadMedia, в которой автор является директором и одним из соучредителей, была как раз и создана для того, чтобы отвечать требованиям этого нового этапа развития, и, насколько можно судить, является единственной, предоставляющей услуги в реальном времени в соответствии с этой новой концепцией. Пока не известно, на каких параметрах (контекстах) будут фокусироваться Netflix и другие, когда они тоже присоединятся к этому направлению, но XroadMedia и наши клиенты — Zatoo, DVBLogic, Technisat — уже над этим работают.